In some corners of the cloud market, business continuity is evolving from a process of failure and recovery to a set of built-in features for resiliency.
This is most often seen within new Web-based applications, as cheap and widespread public cloud resources make highly available infrastructures more feasible. But it is not yet certain that such features will find their way into more of the everyday applications that enterprises use. Logistical barriers to cloud-based resilience include regulatory compliance, cost and required changes to how applications are designed.
“At the end of the day, everything fails … [and] you need to build for that failure,” said Jeremy Przygode, co-founder and CEO of Los Angeles-based Stratalux Inc., an Amazon Web Services (AWS) reseller.
Whether enterprises are willing to bake resiliency into apps “depends upon the application, the complexity and how much people want to pay to make it happen,” Przygode said.
The Model: Designing for Failure in the Cloud
Web companies that have been able to design infrastructures from scratch during the cloud computing era say cloud outages are mere hiccups in their services because of resiliency built into newly written applications.
When Amazon.com had an outage in June, e-commerce website Decide.com barely felt any impact “because we’re geographically distributed, and we’re set up to handle issues as long as it’s not across all of Amazon,” said CTO Kate Matsudara.
Decide’s services are redundant in different Amazon Availability Zones, a construct within Amazon’s cloud that allows machine instances to be placed in locations that are isolated from one another. Any mission-critical service that touches customers is available in more than one place, Matsudara said.
“When the Amazon outage happened, we did get paged and notified, but when we saw that, we just added more capacity in another zone, and then that was it,” she said. “It was very easy and very common—these things happen in the cloud, so you need to design for that and prepare for it.”
The company’s software has also been designed to “fail gracefully,” she said.
“There are a bunch of different design patterns that you can use,” she said. “The one that’s coming to mind is a circuit-breaker pattern, where you have the idea of a downstream dependency, and set your software up so if it’s not there, you’re able to still give updates to the users.”
For example, if a Decide.com catalog went down, say, one that sold sporting goods—the software that runs the website should not allow visitors to click on “sports” but should continue to serve other sections normally.
Other Web companies running on Amazon Web Services are also working toward built-in application resiliency. Netflix, for example, considers such resiliency so important that it has designed and open-sourced a utility called Chaos Monkey, which randomly shuts down Amazon Machine Instances to test whether its applications can survive infrastructure failures.
The Vision: Multi-Cloud Failover for the Enterprise
While redundancy within AWS works for Web companies, true resiliency suitable for enterprise apps requires crossing multiple clouds, experts say.
“It’s already inherent within Amazon, that [design-for-failure] mind-set, but … Amazon as a company can be a single point of failure,” said Przygode.
“Any cloud app that needs resiliency should run in any cloud and not be tied to a specific cloud,” said Edward Haletky, CEO of The Virtualization Practice LLC.
Thanks to common programming languages and network virtualization, cross-cloud resiliency at the application level is technically possible today, according to Haletky.
“If I’m talking [about the] application, I can design a Java app or a PERL app or PHP or even C app to cross multiple networks using physical or virtual VPNs to string my Layer 2 network together,” he said. “It is possible to do it, but the thing is, do you want to, and can you handle the expense of doing it?”
The Challenge: Hurdles Between Enterprises and Cloud Resiliency
While such designs are technically possible, significant barriers remain between today’s enterprise applications and a more resilient, geographically distributed future.
To prevent application failure, an app must be designed with its elements loosely coupled so that one component’s failure doesn’t take down all the components that depend on it. App components also need to be redundantly deployed and able to take over for one another.
“These are big changes for many traditional enterprise apps,” said James Staten, analyst at Cambridge, Mass.-based Forrester Research Inc.
Take databases. Systems such as MySQL were designed to run in one location and be the primary data store for applications, according to Andrew Gross, developer operations at Yipit, a Web company that filters daily deals from sites like Groupon.
Two MySQL databases—or two halves of a MySQL database modified to run in a distributed, resilient architecture—might have the same key for different data. The first record in one database may be a user address in California, for example, while the other is a user address in New York. It’s not simple to bring the two together because they both want to say that their first record is the correct one.
“To get around that, you have to have your application keep track of that information itself and have some other way of saying, ‘The first record is actually this one,’” Gross said. “There are also other problems with that, like making sure the two halves know which half is talking to what.”
As a result of these difficulties, Web companies such as Netflix have embraced distributed databases. Gross said he’s evaluating Cassandra, among others.
“It’s getting to the point now where we’re not really looking to find one database that’s going to suit all of our needs, but looking for different databases that speak to the different purposes we have for them with respect to our application,” he said.

In the meantime, there’s also a website to keep up and running, and time to do this kind of investigative and development work is limited, according to Gross.
Such work can also be costly, Przygode noted. “People talk about ‘You want to diversify your cloud providers,’ and that’s all well and good. But the technical reality is a lot more challenging, and people generally don’t want to spend the money,” he said.
When enterprises pick a cloud service provider today, inertia often sets in, according to Przygode.
For instance, instead of launching an Amazon instance and installing SQL Server on it, users buy into Amazon Relational Database Management Service, which builds in redundancy and high availability on the back end.
“That’s good for Amazon because once you use that, it’s more of a lock-in, and it’s hard to migrate off of that,” Przygode said.
Even if native interoperability between clouds existed and if distributed applications were a snap, the kind of data movement needed to run geographically distributed, resilient cloud applications among different service providers would still pose barriers, according to Haletky.
Being able to run an app from anywhere would be ideal, but doing that “requires you to … not move data around because of all the different treaties and laws for international data usage,” he said. “It’s a vision, but I don’t think we’ll get there as long as the treaties are the way they are… even if [data movement’s] just [within] the United States, you have to be cognizant of state and federal laws.”
The Future: Predictions for Enterprise Applications in the Cloud
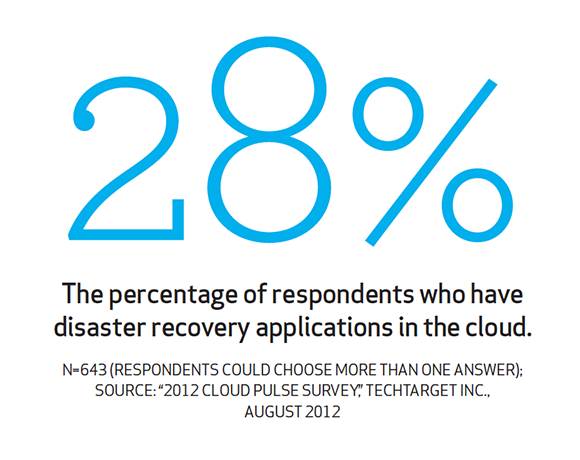
Some industry observers believe that built-in cloud resiliency will become a tool in the business continuity and disaster recovery (BC/DR) toolbox but won’t take the place of today’s familiar DR procedures.
“It’s going to be [for] applications that fit architecturally, applications that can virtualize and fit in a loosely coupled world,” said Forrester’s Staten.
Other industry observers predict that in lieu of overhauled apps that take a licking and keep on ticking, modern DR within the cloud for enterprises will mean a hybrid approach between the traditional static secondary site and the ability to almost instantaneously conjure up new resources in the cloud.
“One of the things we’ve been kicking around early on … is a concept called ‘pilot light,’” said Kris Bliesner, CEO of 2nd Watch, a cloud computing consultancy and systems integrator in Liberty Lake, Wash.
With pilot-light DR, an IT shop would build out a fraction of its infrastructure on Amazon, only scaling the infrastructure up to full size in the event of a disaster.
“We’ve seen companies with three- to four-hour [recovery time objectives] be able to stand up DR environments within Amazon at a fraction of the cost [of a physical secondary site],” Bliesner said. “Pay as you go and [Amazon’s] really vast capacity allows that concept to become reality.”


0 comments:
Post a Comment